robots.txt Intel Gathering Tool
I built RobotsRecon mainly because I like to automate certain tasks that I do often. What is RobotsRecon exactly? RobotsRecon will automatically read a given websites robots.txt file, and check each disallow entry to see if that directory exists. What exactly is a robot.txt file? Webmasters (I am showing my age…) utilize this file to give instructions to web robots like Google and Yahoo! that crawl websites to index them. Before a robot crawls your website to index content, it first checks the root of the website to see if this file exists. This file contains information like which directories it is allowed to crawl, which directories it is not allowed to crawl, rates at which it can crawl websites, and it even allows you to set specific instructions for certain robots to follow.
Why is this useful?
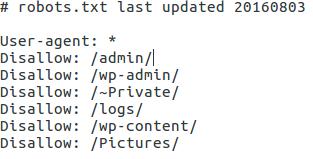
This file can be extremely useful, because webmasters will sometimes explicitly add private directories to the robots.txt file specifically because they do not want a search engine to index (You would be surprised what a search engine can find…). These entries can potentially contain directories with a wealth of reconnaissance information ranging from configuration files, backups, and even passwords. This file is also sometimes not updated when directory structures change, making manual testing if the directories exist quite a chore. I have seen robots.txt files with hundreds of directories listed. Below is a screenshot of a robots.txt file. Something tells me there may be interesting content inside some of those directories…
RobotsRecon Download and Use:
You can find my GitHub repository containing the download and usage information at https://github.com/BrandonEckert/RobotsRecon